Last Updated: 2/6/2023
Introduction
Before talking about specific algorithms or more complex concepts, it is essential that you know the most common problems that can be solved using Artificial Intelligence.
To simplify the explanation, we will assume that all algorithms are black boxes capable of transforming the input data into the expected output data or simply converting it to another format.
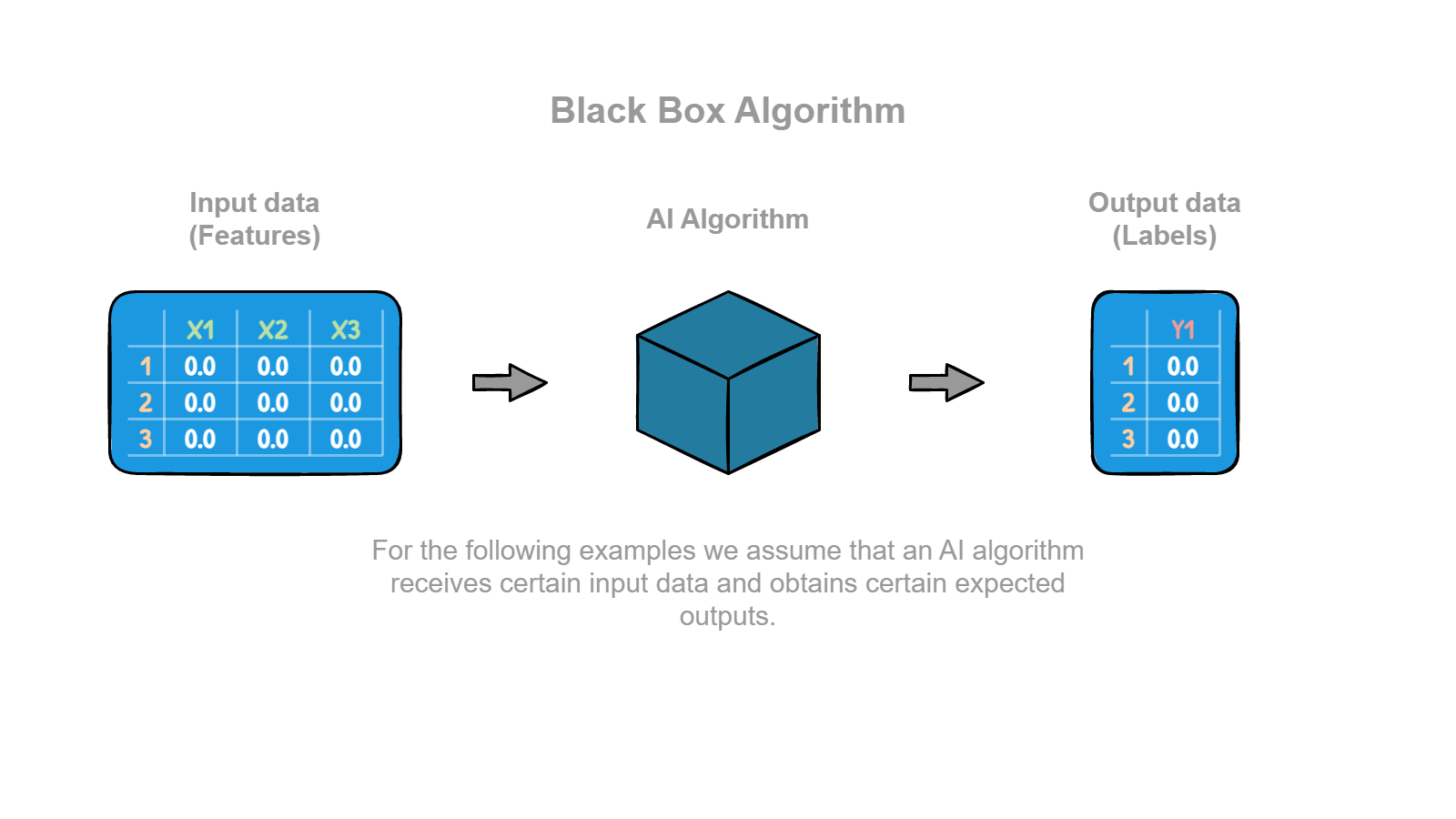
This diagram generalizes any artificial intelligence system and contains all the key elements to understand any problem. The table to the left of the box represents the input features. At the same time, the table on the right represents the output labels. In both cases, the numbers (1, 2, 3) represents the identifier of each sample (a.k.a. as rows). X1, X2 and X3 represent features (a.k.a. as columns), and Y represent the labels. The box represents the artificial intelligence algorithm. Each input sample is associated to an expected output and predicted label.
Most Artificial Intelligence courses focus a lot on the math and the code behind each algorithm, so they use so-called "toy datasets" (such as California Housing, Iris Flowers, Titanic dataset, Diabetes, ... ) to put into practice the knowledge acquired. However, these datasets are trivial and do not represent problems we may face in real life. MLGuru uses a different approach; first, it explains each problem Artificial Intelligence and demonstrates how to solve them with real-life examples. The idea is to cover as many scenarios as possible. For example, to explain classification, instead of just staying with the iris dataset, we will also explore how images, audio files, or text can be used as input data. This approach has two benefits: first, it motivates the student with real life examples, which they can extrapolate to solve similar problems, and second, it makes it easier to understand the algorithms without the need for math or code. The reader chooses if he wants to go deeper or not. Once the person understands the problem, it is much easier to know how to solve it Step-by-step. After this, we provide the code and the mathematical foundations for those who want to learn more.
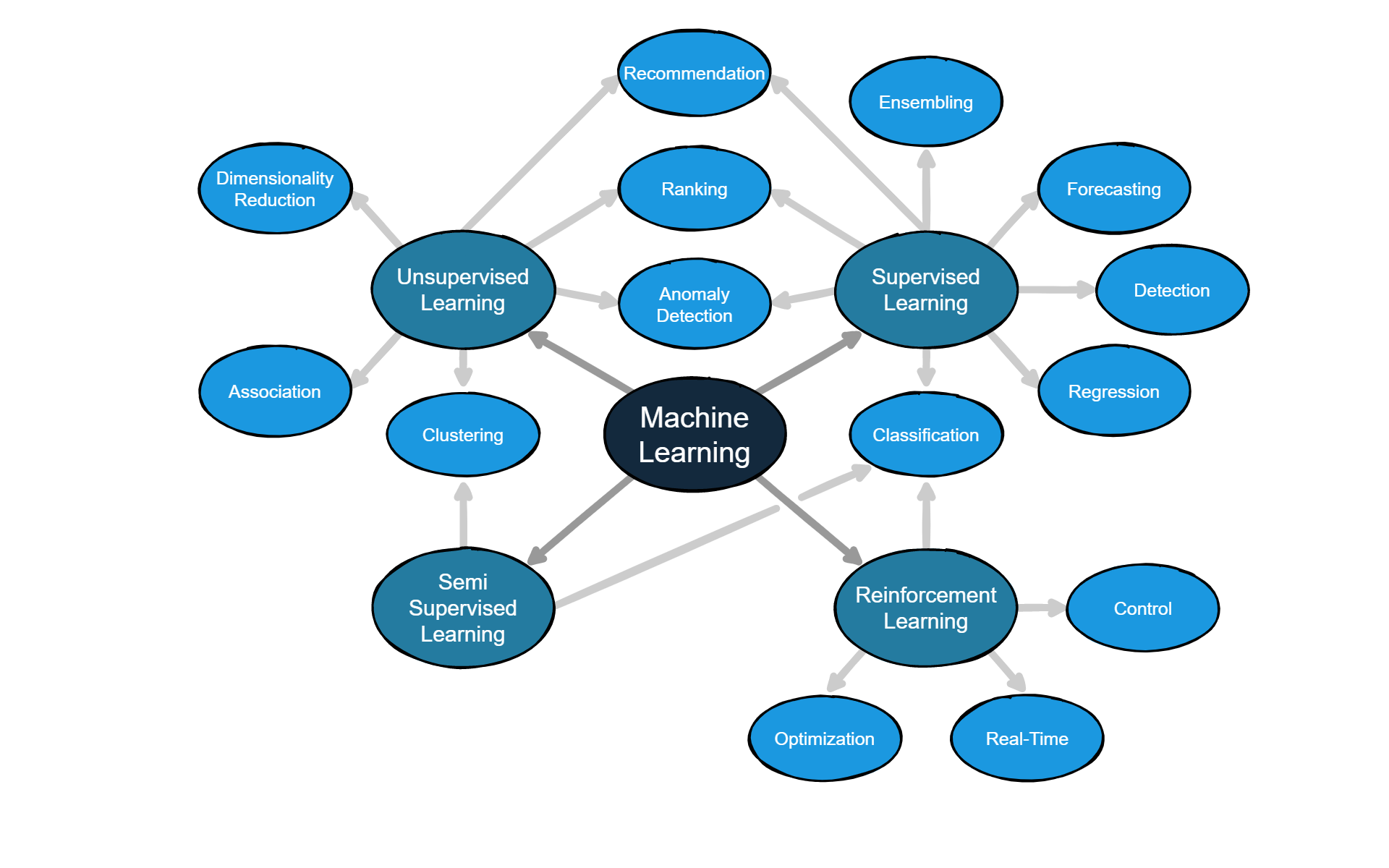
As you have seen in previous pages, there are four types of learning: supervised, unsupervised, semi-supervised, and reinforcement learning. Without going into the details again, each type of learning can solve specific problems:
- Supervised learning can solve classification, regression, detection, forecasting, recommendation, ranking, and anomaly detection problems. Remember: In supervised learning, the algorithm requires the expected results before training. Once trained, the algorithm receives new input data (which it may or may not have seen before) and must predict the labels for this new data.
- Unsupervised learning can also solve recommendation, ranking, and anomaly detection problems, but it can reduce dimensions, find associations, and group similar elements together (clustering). Remember: These algorithms do not receive expected labels before training. Our job is to analyze why the algorithm labeled the input data the way it did.
- Semi-Supervised learning is a midpoint between supervised and unsupervised. It is used to group or classify samples. It is handy when we don't have all the data labeled.
- Reinforcement learning allows us to solve classification problems, but it is also the only one that can solve automatic control, real-time, and optimization. Remember: This type of learning is used when the solution to the problem is unknown, has multiple solutions, or requires a specific set of steps with long-term consequences.